A Retrospective on CPSWeek - Thoughts on the Future of CPS Research and CS Conferences
Posted on May 12, 2025 by Gabe Parmer
I recently went to CPSWeek, a “multi-conference” broadly focused on building high-confidence and trustworthy computational systems that control the physical world. Think autonomous vehicles, robots, the smart grid, airplanes, and good-ol simple embedded systems. The CPSWeek conference include
- RTAS focused on systems implementation for latency-sensitive (e.g. real-time) systems,
- Sensys focused on networked embedded systems with a focus on applications,
- HSCC focused on embedded systems control, and
- ICCPS focused on the various aspects of cyber-physical systems.
I’ll cover a lot of ground in this post. Feel free to skip ahead.
- A debate on the future of CPS research.
- The RTAS conference.
- Killing conferences.
- Are CS conferences obsolete?
Data or Models? - A Debate for the Future of CPSWeek
Most CPSWeek papers are concerned with understanding how to create trustworthy CPS systems. “Trustworthy” here is a load-bearing term, and differs in definition across conferences. For example, in RTAS, it often means that we want to have predictable timing properties of our systems, so that we can, with limited hardware, accurately control the physical system.
There was an interesting debate that focused on the motion:
This House contends that the inherent complexity of modern engineering challenges renders exhaustive mathematical analysis overkill, and that an iterative, adaptive design approach should be prioritized—even for life-critical systems.
The most important word in the motion is “prioritized”. Without that, it is easy to vacillate between both sides.
The arguments for and against were complex and reasonable. My take-aways (which might not map well to the arguments) follow.
Side “prioritize progress”:
- Data- and ML-driven approaches (i.e. those based on Neural Networks – NNs) are driving progress, and will for the forseeable future. Thus, we should prioritize enabling these statistical techniques to solve our problems.
- The Computer Vision community long-ago acknowledged that data-driven ML techniques (e.g. CNNs) won. These are much more capable of performing more tasks, more accurately than approaches that rely on models.
- A focus on models, specifications, and formalism don’t scale, and will be left behind as the world demands stronger features and capabilities.
The best representation of implications for the community was from Anthony Rowe. He shows a sequence of (AI generated) images with a T-rex representing the CPS community, and a meteor representing ML. 1. The meteor speeds toward the world of CPS dinosaurs, leaving only time till they are wiped out, 2. a proposal for what the community should do with the T-rex hopping on, ridding, and hugging the ML meteor, and 3. the next pane showing the T-rex juicing the ML meteor for all its worth.
Side “formal methods”:
- Yes, we must use NNs, but we should build guard-rails, and those must be prioritized.
- Formal methods cannot provide the necessary features and capabilities, but they can focus on the areas that require safety – the example given was that the paths in a nuclear power plant for shutting down to avoid a runaway reaction are rigorously analysed, while the rest (including power generation) are not. Focus on mathematical rigor on the parts that define safety, and nothing else.
- If we don’t have a formal specification of what a system is supposed to do (and not do), it becomes hard to integrate it with the broader system. A core part of formal analysis and modeling is specification, which will always be relevant.
Summary. Given that Neural Network approaches have unambiguously won in most domains, this argument should be taken seriously. That said, it should be weighted against safety concerns. In the end, society will define the risk thresholds that will likely determine if the formal methods side has legs. History shows that we have a very low threshold for airplane crashes and nuclear power incidents. However, as CPSes impact our day-to-day lives in vehicles, will the threshold change? We’re certainly OK with some level of car accidents.
For the community, I don’t see a world in which people don’t submit NN work. And there will be reviewers receptive to that. The risk is that the conferences largely receive low-quality NN work, and lose relevance due to that – what differentiates CPS NN work from the rest? There will also be quite a few reviewers receptive to traditional methodologies. If formal methods end up having no place in modern system design, this is an existential risk.
I share this without much skin in the game. I build systems, and will use any applications to evaluate our system that are interesting. I deeply appreciate both formal methods, and ML approaches.
Debate outcome. The formal methods side “won” the debate as they converted more people to their side during the debate. I’m sure each of you might read in to that as positive or negative, as a affirmation for formal methods momentum, or a harbinger of the community’s demise. Time will tell.
Real-Time and Embedded Technology and Applications Symposium
RTAS is one of the top three or four real-time and embedded conferences and is the one most focused on system implementation. As such, it is often the most interesting to me. I spent most of my CPSWeek time at RTAS.
RTAS is focused relatively generally around systems that explicitly consider and are designed around latency properties. This includes real-time systems (in which we often want to ensure that computations complete by a deadline), but also other latency-sensitive systems such as edge infrastructure. The past few years, the Call-for-Papers (CfP) had a somewhat vague definition of what work was to be considered for the conference (mainly, is embedded work that doesn’t explicitly consider latency in-scope?), but I believe it will be broadened to a definition that will admit embedded work. I consider the past years a regression, and I hope we are returning to something approximating the older CfP wording.
A Sampling of Interesting Papers
The RTAS program had a number of interesting papers. I’ll start with our papers, which are quite interesting to me 😉.
Our Research: Shielded Processor Reservations
Esma presented our work that is a collaboration with Björn Brandenburg on SPR: Shielded Processor Reservations with Bounded Management Overhead. SPR identifies a number of attacks on the reservation systems that are supposed to provide temporal isolation on modern systems, including the core mechanisms in cgroups, SCHED_DEADLINE in Linux, Xen, and seL4. We observe that these systems tend to have strong theoretical properties, but that the implementations are susceptible to attacks. These mechanisms use budgets to track rates of thread execution, decreasing the budget with execution. When the budget is expended, the thread is suspended until a replenishment of the budget. The replenishment processing requires timer interrupts, and scheduler logic to process each replenishment, and 2/3 of our attacks focus on this. They
- drive up this bookkeeping processing overhead, and
- target that overhead on the execution time of a high-priority thread
to cause the high-priority task to be massively delayed in its processing. This is harmful in, for example, autonomous vehicles where the processing of sensor input, or pedestrian detection can be arbitrarily delayed.
We previously published the thundering herd attack on seL4’s reservation mechanism. We essentially force the scheduler to process many attacker thread’s replenishments at exactly the time a higher-priority thread should execute. Additionally, we introduce another attack that causes a cascade of many timer interrupts to process attacker thread replenishments during higher-priority thread execution. Last, we show that higher-priority threads can cause lower-priority threads to make only stunted progress with their reservation by constantly preeempting and causing cache-interference.
SPR prevents all of these attacks by
- ensuring that when the scheduler executes, it processes only a constant number of reservations (to avoid the first attack),
- properly prioritizing timer interrupts to guarantee that if a timer fires, it will lead to a preemption (thus allowing only necessary timers to avoid the second attack), and
- using non-preemptive sections (a technique for which there is a ton of literature) to prevent low-priority thread preemption for a span of time that enables efficient cache usage and effective progress (and mitigate the third attack).
Together SPR hopefully represents the final-say in how to enable reservations that not only provide rate-limited security properties, but are themselves efficient and safe. Esma implemented and evaluated SPR in our Composite scheduler component (in Composite, schedulers are in user-level protection domains). We’ll pull it into the Composite mainline branch after some cleanup.
This was Esma’s first academic presentation and she did a great job!
Our Research: Janus
Wenyuan presented our work on Janus: OS Support for a Secure, Fast Control-Plane. A lot of previous work has focused on decoupling the control- and data-plane, and optimizing the heck out of the data-plane (see Arrakis and Ix, for example). But in systems that require the dense deployment of multiple tenants on shared hardware (e.g. at the edge), the control-plane deserves love too. Janus enables
- strong isolation (temporal and spatial) for multiple tenants,
- with efficient control-plane operations for multiplexing resources, and
- configurable control-plane policies to best use limited resources.
The core idea is best captured with a picture:
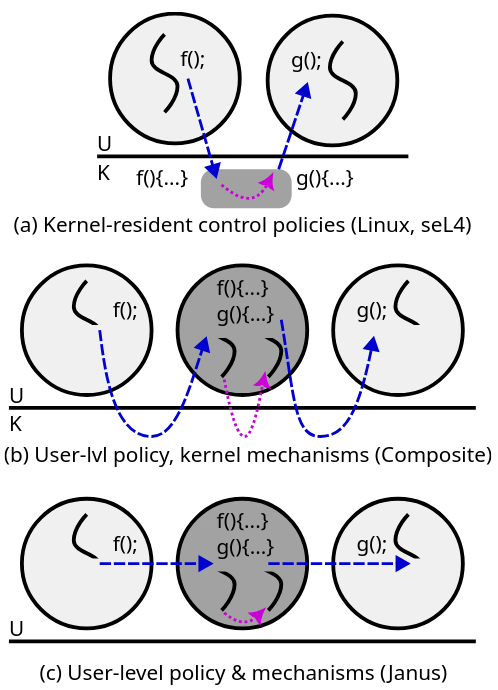
We achieve this using x86’s Memory Protection Keys (MPK), which provide instructions for the user-level switching of protection domains. MPK has been used in quite a few systems (e.g. Erim, Hodor, Donkeys, Endokernel, Underbridge, \(\mu\)switch, etc…), but Janus provides a number of unique contributions as the only system to:
- create an OS tighly integrated with MPK by ensuring that MPK-based protection domains use and provide identical abstractions to normal page-table-based protection domains, and that the strong capability-based security of the underlying OS directly maps to the access control of MPK avoiding the semantic gap between in-process protection domains and the OS-provided abstractions,
- provide abstractions (our split primitive) that enable an unbounded number of protection domains that can leverage MPK-based IPC to system services (despite the MPK limitation of 15 domains per process),
- we solve a CFI issue with most MPK papers in which threads can “return” from a callgate without correspondingly previously “invoking” it, and
- we show how these facilities can be used to massively improve latency and throughput properties of existing systems.
Results. The results are particularly strong.
First, we show that we can implement L4-style IPC (synchronous rendezvous between threads) as a custom control policy in the (user-level) scheduler component that is faster than IPC in seL4. This is a surprising result, as our policy requires IPC to the scheduler, and the scheduler dispatching between threads. Naively, if we implement fast (L4) IPC using both IPC and dispatch logic in Composite, it should be slower, but in Janus it is not!
Second, we show that Janus can transparently increase the performance of complex systems. Benchmarks in the security-centric, multi-protection domain, Patina RTOS show that we can achieve up to 3x faster performance than Composite, and 6.5x faster than comparable operations in Linux.
Finally, providing \(\mu\)-second service to memcached, we show that we can get 5x throughput increases, and multiple order of magnitude 99p latency decreases by combining our MPK-based fast control-plane with custom policy. These are performance increases on the level of Shinjuku & Shenango, while enabling strong isolation. The evaluation includes multi-tenant scenarios similar to Splinter.
It takes a village. This is work has been quite the journey. It started around FOUR years ago, and was performed by a large (for our lab) collection of students.
- Wenyuan focused on the design of the protected dispatch logic, on integrating everyone’s work, and on the core scientific evaluation of the system.
- Xinyu did a ridiculously huge amount of research and engineering to make this work possible including (but not limited to): porting Composite to
x86_64(yes, we were a dinosaur before), updating DPDK to work with the system and define a many-core usage of DPDK that scales effectively, and portingmemcachedto the system while enabling multi-tenant client protection domains to harness the service. Much of this work also contributed to and enabled his byways research. - Undergraduates Linnea and Evan contributed a new mechanism for virtual address space management to enable an unbounded number of processes to use fast MPK-based IPC (despite MPK’s limit of 15 protection domains in a page-table), and the engineering around shared memory and the core PPC mechanism, respectively.
- Phani previous contributed his Slite (scheduling light) work that enables schedulers to avoid needing to make system calls to switch between threads – thus making user-level scheduling of system threads faster than conventional kernel-based scheduling.
All of these individuals are top-class researchers, but are also spectacular low-level system hackers.
Wenyuan and Xinyu are looking for a job, so please reach out if this sounds interesting. Wenyuan’s looking in the US, and Xinyu’s looking in China.
Other Interesting RTAS Research
A sampling of other interesting papers (I have a strong bias toward implementation work, sorry if I didn’t sample your work!!!):
- Björn presented his lab’s work on LiME: The Linux Real-Time Task Model Extractor. A core problem with real-time systems is that we require a mathematical model to describe the execution of tasks in the system, but most systems “in practice” don’t provide that model. Can we reverse engineer a tight system model from a system’s execution? LiME answers this question by monitoring the system using eBPF, and defining heuristics to create system and task models. I’m very proud of Bite’s involvement in this work as he is an alumni of our lab at GWU
- Rodolfo presented his lab’s work on ParRP: Enabling Space Isolation in Caches with Shared Data. Real-time systems have been trying to solve a core issue for almost 20 years: how do we know how long something will take to execute, when computations on another core are contending a shared Last-Level Cache (LLC)? This paper provides a minimal cache bookkeeping update to enable logic across cores to have predictable interference in the LLC even when sharing memory. A cool result, with current work being done to synthesize it into FPGAs.
- A Design Flow to Securely Isolate FPGA Bus Transactions in Heterogeneous SoCs. As argued in the Barrelfish paper, systems are actually distributed systems. A number of busses connect memory, processors, FPGAs, and I/O and each of these end-points can generate traffic that can maliciously interfere with other end-point computations. The background for this paper is cool in that it spells out how this interference can happen on Xilinx FPGA systems, and defines a set of protocols and innovations to securely isolate end-point communications over these busses.
- CROS-RT: Cross-Layer Priority Scheduling for Predictable Inter-Process Communication in ROS 2. There’s been a lot of work on making ROS predictable, but its execution model is…not quite designed for it, we’ll say. I’m not so excited about ROS for reliable systems, but it absolutely has won, is immensely popular, and has a ton of code available. The question is, can ROS go from roboticists with tons of spare resources where rare failures don’t really impact things, to highly certified systems with limited resources? This paper looks at communication across layers (including kernel threads), and identifies potential priority inversion issues, and attempts to minimize or remove those inversions. We’ve studied this quite a bit across complex OS software stacks (but not in ROS), and the authors provide a relatively comprehensive approach. A colleague who does some of this work in making ROS predictable was less impressed than me as they would like to see the community making the current ROS stack predictable, rather than updating it to solve issues. While this is a fair point, motivated by more direct impact, I still appreciated this work.
If you presented any of these works, or have links to your papers, let me know and I’ll update this list.
A Note on VISAs
Many more papers were presented by professors than in any conference I remember. This was a sad reflection on the challenges for lead students to get a VISA to present their own work. This is sad from multiple perspectives:
- Doing a PhD includes learning how to communicate your research to the world, so students don’t achieve this if they can’t present their work.
- Students that present their own work build their “brand”, making them more competitive for future jobs.
- There are active discussions on avoiding US-based conferences until the VISA issues are sorted, which hurts our competitiveness.
I’ll just say that I hope these issues are resolved sooner than later.
Creating and Killing Conferences
This multi-conference has an interesting history of recent updates, and potential future changes:
- IoTDI was added to CPSWeek somewhat recently with a focus on IoT,
- CPSWeek updated its name from “Cyber-Physical Systems Week” to “Cyber-Physical Systems and Internet of Things Week”,
- this year Sensys, which was not previously part of CPSWeek was added, while merging it with IPSN (another conference on sensor networks) and IoTDI,
- there is a query to attendees involving potentially merging ICCPS and HSCC.
There have been many years of relatively stability in the conference line up, yet massive changes this year, and potentially in the future. The emphasis for everyone I talked to was on merging conferences, not “killing” them. But for me this is a distinction without a difference. In the end, we’re taking multiple conference venues that each accept publications, and merging them into a conference that accepts fewer. So I’m going to argue that we’re simply killing conferences.
And I think this is brilliant. Academics get “credit” and positive reinforcement for creating conferences. It shows “leadership”. I’d argue strongly that outside of massively expanding fields (e.g. current ML), we should not be creating conferences. Why?
Kill More Conferences
Each conference needs a set of papers that are competitively selected via peer review. That means each conference requires a program committee of volunteer researchers who are willing to spend time reviewing submissions (often four-per-paper). There are only so many volunteer hours out there, so this eats into the global pool.
Much worse, there’s only a finite number of papers generated each year, and only some small fraction of them are generally “strong” (say at maximum 25% of those submitted to a conference). When we create conferences, we’re often just providing a venue for those papers that aren’t as strong to be published. This might (in some countries) help satisfy grant and departmental “bean counting”, but I’d argue it has massively hurtful to the community. When a massive amount of work is published in a community that is not of a high standard, the community suffers. It devalues the average publication in the community, and makes it impossible for those outside of the community to understand where to find strong, relevant research.
So while I don’t know the background behind killing IPSN and IoTDI (and potentially pruning out one of HSCC/ICCPS), I applaud the community for doing so. When submission rates, and quality submissions go below a count that can sustain quality, that conference will only drag down the reputation of the community (note: I don’t know if that’s what happened here).
But Don’t Go Overboard
While I was at CPSWeek, I learned that USENIX ATC was also axed. “Great, another conference killed”, right? No. USENIX ATC (henceforth USENIX) has a long history of strong publication as “the hacker’s conference”. The attendance to USENIX was falling off since 2020, it seems, despite strong submission numbers, and strong conference outputs. This is a strange case where people didn’t want to go to the conference, but the output was quite strong.
I believe this is a canary in the metaphorical coal-mine of the academic conference world. Do we need to update our view of conferences?
Hot Take on Computer Science Conferences: Obsolete?
I haven’t been to a huge number of conferences since Covid. I forgot how much they simply don’t feel like the right way to do science anymore. I very much enjoy:
- social events that would otherwise not be possible such as the debate noted above, and
- the ability for students to present and be integrated into the scientific community.
These are quite valuable. Things I do not enjoy:
- The amount of money and time spent on globally converging on a place is non-trivial. It is possible that grant money is going to be more challenging and limited in the future.
- I cannot reasonably intake all of the information that conferences provide over a three day period.
- Most conferences have around 3-6 papers that I actually care about, making the time-for-knowledge trade-off not fantastic.
- The amount of organization (esp. for local arrangement chairs) they require is somewhat off the charts.
I’m not convinced that we’re landing on the good side of these trade-off. At the core, I don’t find a synchronous approach to be necessary for effective CS research dissemination. That said, I’m hesitate to take this argument too seriously as it would hurt student integration into the community.
I believe that peer-review is valuable (though in many domains it is buckling under the pressure of thousands of submissions). But we can maintain peer review without having a physical conference. We can have conferences that look a little more like journals. Our time might be better used by promoting our own work online, and creating online communities for doing so effectively.